


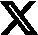


Online, a number of commentators picked at very significant limitations in the study. I agree; the study is extremely flawed. But it’s one thing to say that the study is problematic and another to unpack it and think about what might have been done differently. Which is what I want to do today. The TL;DR is that I do not see any compelling reason that the evidence should make you any more worried about this issue than you were before seeing the study.
I’ll talk it through in a few steps:
- What does the study do and say?
- What are the inherent problems and data limitations?
- What could it have done better?
- Why is this in the MMWR? Why did the CDC put it out?
What does the study do and say?
You can read the MMWR study here. Very broadly, what the authors do is take two sources of medical claims data — this is data that reports diagnoses for individuals, based on insurance records — and explore the relationship between COVID-19 and the subsequent development of any type of diabetes in children.
More specifically: the authors identify patients who were diagnosed with COVID-19 at some point between March 2020 and February 2021. In one data set, this is based only on diagnosis; in the second it is also based on those with a positive COVID test. The authors then create an age-and-sex-matched comparison group of children who did not have a COVID-19 diagnosis during this period.
For the COVID-19 patients, the authors define the “index date” as the first date with a claim for COVID-19 or the first positive test. For the non-COVID patients, they choose a randomly selected claim date as the index date. They then analyze the number of diabetes diagnoses in the two groups in the months after the index date. This is a fairly common empirical approach, and it makes some intuitive sense. Basically, they want to ask whether a diabetes diagnosis is more common after a COVID-19 diagnosis than in another group after a randomly chosen non-COVID medical encounter.
What the authors find when they do this is that there are more diagnoses of diabetes in the month after the COVID-19 diagnosis than in the random following month in the non-COVID group. The overall numbers are small. For example, the authors find in the COVID-19 group an incidence of 316 diabetes diagnoses per 100,000 individuals per year. But the COVID-19 diagnosis group is consistently higher than the matched comparison group. The effects are more consistent for the 12-to-17 age group. And the authors show that this effect doesn’t show up if you look pre-COVID at other respiratory infections. That is, we do not see this effect after a flu diagnosis in 2018.
The diabetes diagnoses in the paper include both Type 1 and Type 2 diabetes, and the authors do not separate them out, so it is not possible to learn which type is driving these results.
The paper concludes that the data shows an increased risk of diabetes after COVID-19 infection for people under 18 and emphasizes the importance of vaccination.
What are the inherent problems and data limitations?
There are (at least) two important problems with this study. By far the most important is that the authors are unable to control for any characteristics of individuals other than age and sex.
To see why this is a problem, consider the issue of body mass index. Children vary in their BMI, and it is well-known that a higher BMI correlates with a greater chance of a Type 2 diabetes diagnosis. In addition, a higher BMI is also correlated with a greater risk of COVID-19 (not necessarily having it, but having a serious enough case for it to be detected). This latter point was made recently by the CDC in another MMWR piece.
What this means is that the population of children who have COVID-19 are more likely to have a higher BMI, and that higher BMI is associated with a greater risk of diabetes diagnosis. Even in the absence of COVID-19, they would be more likely to be diagnosed just given this risk factor.
Essentially, this is a problem of “residual confounding” or “omitted variable bias.” The two groups — the COVID and non-COVID group — are likely different in a number of ways that the authors do not adjust for. BMI is the most obvious, but others include race and socioeconomic status, as well as other conditions. Without this information, it is very difficult to know if COVID-19 is the cause of the higher rates of diabetes or if it is one of the many other differing factors.
There is a second issue, which relates to timing. Even if COVID-19 didn’t cause diabetes, we might see more diagnoses right after a diagnosis of COVID-19 because the sustained interaction with the medical system prompted diagnosis. Some of the checks the authors do make this story perhaps less likely, and I’d overall rank it as less important than the key issue of omitted variables.
The particular issue of not adjusting for BMI or obesity has been raised frequently in response to the paper. The reason the authors do not adjust for differences in this condition in their analysis is that they cannot do so with the data they have. The paper relies on medical claims data, which reports diagnosis codes but doesn’t have the kind of demographic or health data you’d get in (say) an electronic medical record. With data like this, it is simply not possible to adjust for differences in BMI or race or socioeconomic status.
This doesn’t mean they couldn’t have done better, though.
What could they have done better?
What the authors have to work with here is a long “time series” of data on individuals and diagnosis codes. With this, they could do better than they did.
One improvement to the paper would be to separate out Type 1 and Type 2 diagnoses. These have different diagnosis codes, so it is possible to look at them separately. I am not sure why that wasn’t done.
A second improvement would be to adjust for pre-diabetes. Often, with Type 2 diabetes, individuals are diagnosed with “pre-diabetes” prior to diabetes diagnosis. It’s a diagnosis that comes with some behavior-change advice and perhaps additional monitoring. There is a diagnosis code for pre-diabetes, and the authors could have used that to look at differences across groups, or as a control.
A more involved but more useful improvement would have been to use more of the time variation in the data to, effectively, look for pre-trends. To see how this works, let’s go back to the basics of their approach. The authors have a COVID-19 group and a comparison group, and they compare diabetes diagnosis rates in the month after COVID-19. If they were to put their results on a graph, it would be like this:
But the reality is that they have data from the earlier and later periods that they are not using. It would be possible to, for these same people, look at diagnosis rates earlier and later.1 Why would this be helpful? Let’s think about the graph below, where I’ve added two sets of lines, both of which would be consistent with the data in the paper.
The solid lines — light blue versus dark blue — reflect what looks like a real effect of COVID-19 on diagnosis. Most importantly, the diagnosis rates in the earlier period are similar, and it is only post-COVID that the rates go up. The dotted lines, though, would also be consistent with the numbers in the paper, but they tell a totally different story. They would tell a story of two groups with different underlying risks but where COVID seemed to play little role.
I do not know which graph would show up if the authors had done this. It wouldn’t be hard to do. My strong suspicion is it would look more like the dotted lines than the solid ones. But that is just my instinct. My point isn’t that we can prove that the results are biased in this way; it is, instead, that the paper could have been done better.
In the end, that is my strongest feeling in reading it. This paper is about a possibly important question, and in principle the data seems like it could be informative (up to a point). But the paper isn’t well-done. It’s missing very basic analysis, like separating out Type 1 and Type 2 diabetes. Graphing diagnoses over time isn’t a magical approach I made up for this newsletter; it’s standard for an event. The idea of using other suggestive diagnoses like pre-diabetes for controls is straightforward. There are a tremendous number of fillable holes.
The holes ultimately add up to the point where the paper isn’t informative. Could it be that there is an effect? There could, just like there could have been before you saw the article. But I would say I’m no more convinced of an effect after reading the paper than before, which isn’t a great commentary.
Why is this in MMWR?
I suspect the question has occurred to many of you in reading this: Why is it in MMWR? The outlet has gotten a huge amount of attention during the pandemic, and this particular article was widely covered in major media outlets. I’m far from the only person to notice its glaring weaknesses.
Why weren’t these issues caught in peer review? The goal of peer review, in an ideal world, is to identify basic weaknesses and ask the authors to fix them. The main answer is that MMWR isn’t peer-reviewed, at least not in the traditional sense. Papers undergo a 14-step review process that takes months, but the review is all internal to the CDC. In my experience from publishing there, much of this review focuses on format and phrasing and not on the content of the analysis.
MMWR publications are also an opportunity to put scientific weight behind public health messaging. In this case, the paper ends with a strong push for vaccination for children, a message that the CDC has been trying to send in many ways. I am also strongly supportive of vaccination for children, but there are much better ways to convince people (like this chart about vaccination and hospitalization in New York State).
It’s actually not helpful to try to convince people to vaccinate their kids with poor quality evidence of this type. It gives those who oppose vaccines something legitimate to complain about, and terrifies at least some parents whose kids are not vaccine eligible yet.
I am not sure why this paper was selected for MMWR or what type of review it went through. What I can say is that the paper is deeply flawed, and if you are worrying about it, you should stop.
Community Guidelines